说到内存管理大家会可能想到malloc和free函数。
在讲这两个函数之前,我们先来讲讲栈(stack)和堆(heap)的概念。
1.栈(stack)
我们单片机一般有个启动文件,拿STM32F103来举例。
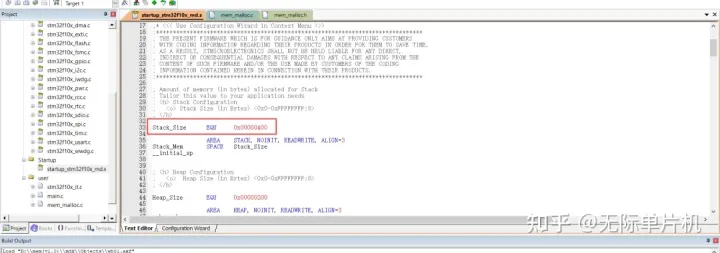
这个Stack_Size就是栈大小,0x00000400就是代表有1K(0x400/1024)的大小。
那这个栈到底用来干嘛的呢?
比如说我们函数的形参、以及函数里定义的局部变量就是存储在栈里,所以我们在函数的局部变量、数组这些不能超过1K(含嵌套的函数),否则程序就会崩溃进入hardfaul。
除了这些局部变量以外,还有一些实时操作系统的现场保护、返回地址都是存储在栈里面。
还有一点题外话,就是栈的增长方向是从高地址到低地址的,这个用得不多,暂时不需要去深究。
2. 堆(heap)
malloc()函数动态分配的内存就属于堆的空间。
同样,在单片机启动文件里也有对堆大小的定义。
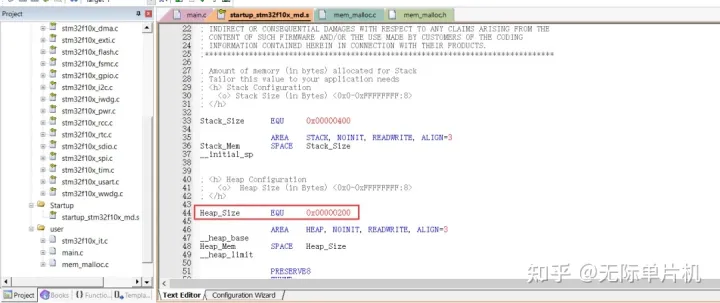
0x00000200就是代表有512个字节。
这意味着如果你用malloc()函数,那么最大分配的内存不能大于512字节,否则程序会崩溃。
网上很多文章说,全局变量和静态变量是放在堆区。
但是我做了实验,把堆的空间大小设置成0,程序正常运行并无影响。
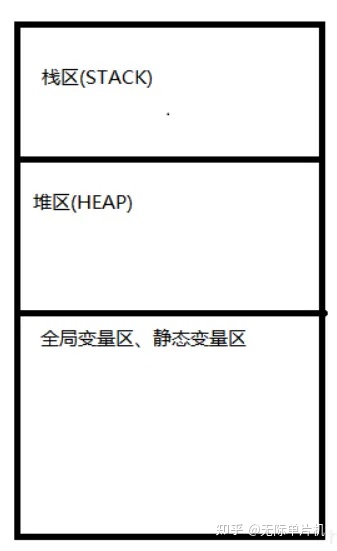
这说明我们平时定义的全局变量、静态变量是不存放在堆的,而是堆栈以外的另外一篇静态空间区域,个人理解,如果有误请指正。
Ok,那么我们简单了解了堆和栈的概念,也知道malloc()函数分配的是堆的空间。
那么下面,我们探讨一个问题,有现成的动态分配内存函数malloc(),为什么单片机却很少用,为什么还要自己去做内存管理(自己写代码实现malloc()和free()等函数)?
malloc()函数经过成千上万网友验证,很容易出问题,所以一般单片机开发没人敢用,除非是…。
而上位机很多就会用,因为lib库里有写好的内存管理的算法,并不适用于单片机。
malloc()用于单片机主要问题体现在容易产生内存碎片。
内存碎片是什么?
内存碎片就是分配了内存空间,但是未被使用的部分。
比如说你用malloc(1)分配了1个字节,但实际给你分配了8个字节的空间,剩余7个就是内存碎片。
那内存碎片是怎么产生的呢?
我们通过程序来演示一下:
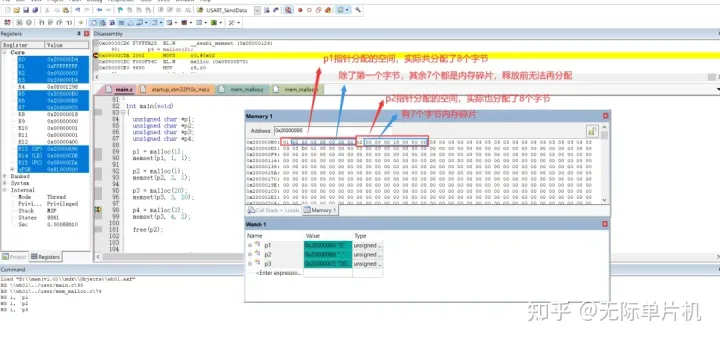
我们在给p1和p2分配的时候,明明只分配1个字节,实际却分配了8个字节的空间,在释放前这7个字节都不能再被分配,相当于7个字节空间就浪费了。
这是其中一个产生碎片的方式,除此以外,还有别的方式会产生。
比如说你第一次连续申请了2个空间,第一块是1个字节,第二块也是1个字节。
理论上分配的空间地址都是连续的,但是中间产生7个字节内存碎片,分配两块的话就是14个字节。
当把第一块1个字节释放以后,第二块1个字节的空间还没释放。
这样相当于第一块的空间只能用来分配1个左右字节的空间了(有可能还可以分配2-6个字节的),具体要看Malloc()函数分配算法。
但可以肯定的是,不能分配像10个字节这么大的空间,那这块空间的应用范围就会缩小了很多。
如果一个程序分配很多1个字节这种小空间,那后面整个内存块会有非常多这种碎片叠加。
最后会导致,明明有很多空闲内存,但是总是分配失败,甚至导致程序崩溃。
所以,这就是要自己写内存管理的原因,就是要解决内存碎片这种痛点。
内存管理由很多不同的子功能组成,比如说动态内存分配算法、内存释放等等。
但是内存管理做起来是比较复杂的,涉及到数据结构和一些小算法。
有些高端的单片机为了帮工程师解决繁琐的内存管理代码,就内置了MMU(内存管理单元)模块。
不过大多数单片机都没有,我自己也没用过,没有的就要自己写代码去实现内存管理。
内存管理可以说是实时操作系统和自己写程序架构的刚需,操作系统一般有自带不用自己写。
一、动态分配内存实际应用有哪些?
拿我们wifi报警主机这个项目为例。
1.用于任务灵活创建
我们的主机自己写了一个小系统,有涉及到任务创建和调度。
我们在创建任务的时候就非常不灵活,需要手工去调整内核头文件的任务数量。

最理想的状态是系统内核文件不用修改任何东西,实际上没动态内存分配根本做不到。
我们这个架构很多产品都能用,每个产品功能不一样,所以任务数量也不一样。
如果有动态内存分配,就可以给大家灵活地创建自己产品需要的任务,而不用手动改,甚至我都可以把架构的代码都封装成lib,直接提供函数接口给不同的工程师使用。
2.用于不确定数量的临时数据
比如说我们主机有配对功能,就是可以通过无线通讯去学习探测器。
然后我们设置菜单有个探测器列表,列表会显示所有已配对的探测器。

如果要把全部已经配对的探测器都显示出来,比如说我主机总共支持配对20个探测器。
那我就要实现定义出能够装下20个探测器的结构体数组。
最惨的是,还需要定义成静态的,不然下次进入这个函数,数据又丢了。
而如果我不在这个菜单的时候,实际上这块内存是浪费了的,如果有动态内存分配,那绝对是相见恨晚。
如果你还不会,赶紧学,迟早用得上!
二、内存管理如何实现?
以前我就在网上找了很多资料和例程,一边找一边骂,结果还是以失败告终。
这块是我一直想突破,一直无法突破的痛,以前也做过,但是一直无法很好地解决碎片问题。
最近运气好,经过一个高手推荐,在Github上嫖到了大神写的内存管理代码。
代码给你没用,知识嘛,学到才是自己的,哈哈。
下载下来,先深度研究,吃透以后改了个小BUG和一些细节代码,搞成Keil能编译的版本。
测试平台是我们的wifi报警项目硬件,基于STM32F103。
下图调试测试环节的痛苦过程。
是不是有种头皮发麻的感觉?那就对了! 码农的脑子从来没有舒服过。
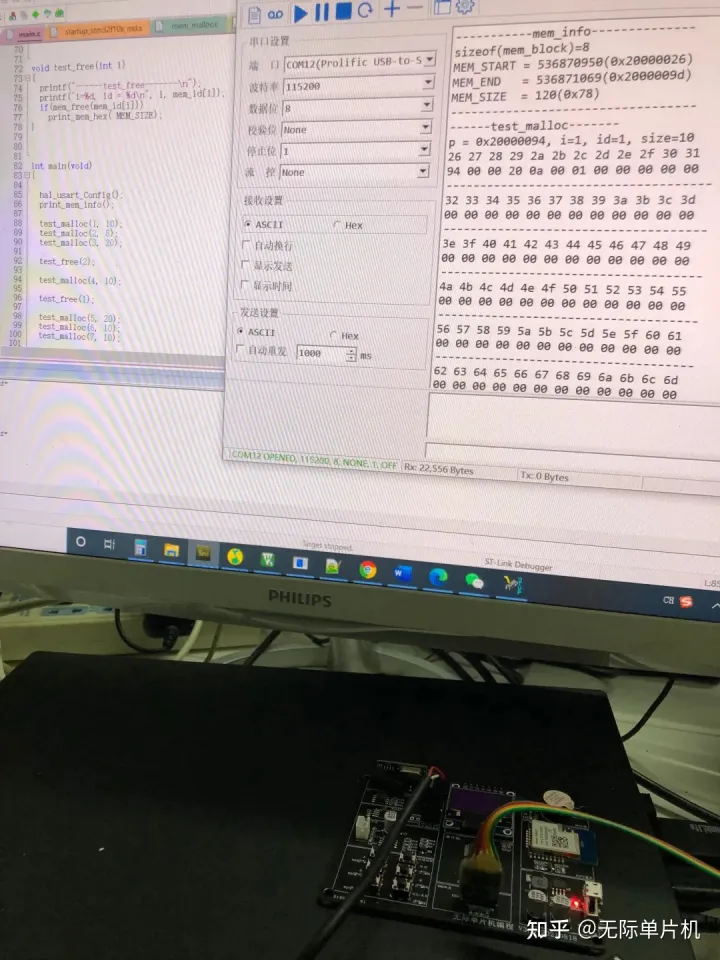
下面是测试数据(有点长,只截取了3/4):

密密麻麻的数据上一行是地址,为了方便调试和显示,我限制了最大只能分配120个字节,然后地址一个字节够用,就把高3个字节地址去掉了。
下一行是数据,2行一组,如下图所示。
Ok,下面进入本篇文章高潮部分,算法如何实现?
1.算法原理
本质就是在一个数组里面玩结构体指针,数组作为内存池。
先定义一个很大的数组,你最大支持多大内存分配,就定义多大的数组,比如说我目前最大支持120个字节,MEM_SIZE就是120。
2.数组存储方式
我们每一次分配内存给这块内存做一张”表格”,”表格”里面记录这块内存的信息。
表格用程序来表示就是结构体,因为只有结构体能表示不同类型数据的集合。
这个“表格”一共会记录内存块3个信息:内存块数据的存储地址、内存块大小、内存块ID。
这3个信息是为后面写动态内存分配和释放内存函数作铺垫的,目的是更好地寻找到指定的内存块。
相当于每动态分配一块内存,都会在内存池(数组)里面分配两块内存空间。
一块内存是用来存储这块内存唯一的表格(结构体),根据结构体成员计算的话就是固定的8个字节。
另一块内存就是实际你需要分配的内存空间大小,最终你的数据就是存在这块内存里。
比如说,当我调用动态内存分配函数mem_malloc(10),分配了10个字节的内存空间,并且全部写入值1。
完成以后,内存池的存储结构如下:
然后,我再调用动态内存分配函数mem_malloc(8),又分配了8个字节的内存空间,并且全部值写入2。
完成以后,内存池的存储结构变化如下:
经过这两次分配内存以后,不知道你发现了没有。
内存是连续分配的,没有碎片。
内存低地址空间保存内存块信息(“表格”),高地址空间分配用户的缓存,有没有感觉跟前面堆栈的使用一样?都是往内存空间中间分配。
数据的低位存储在内存的低地址中数据的低位存储在内存的低地址中(即小端模式)
3. mem_malloc()动态内存分配函数
mem_malloc()函数就是以上面说的分配原理,然后用代码去实现,源代码如下:

这个函数相对简单,注释也详细,大家可以自己研究下。
4.mem_free()内存释放函数
真正的难点也就是在这个函数,主要是去碎片的算法。
先贴上这个函数的代码:
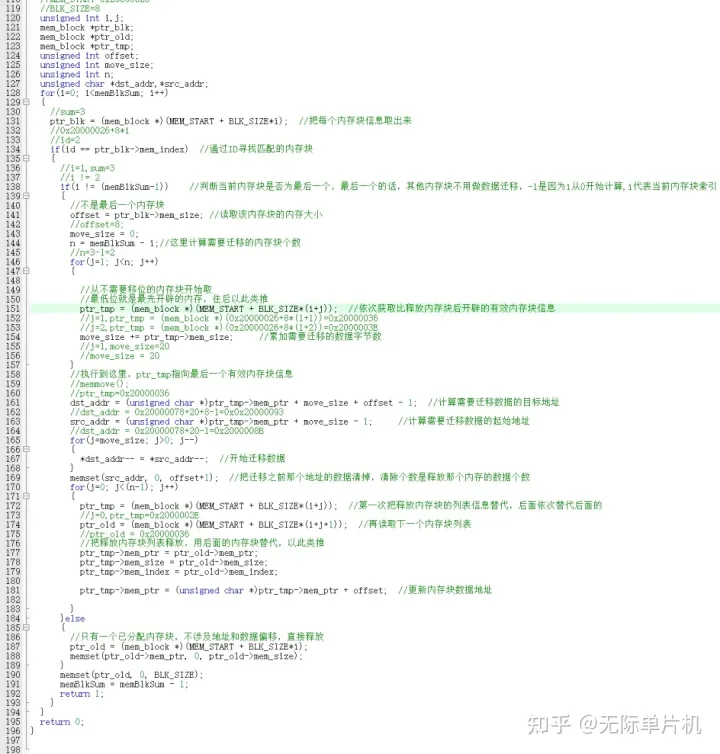
实现原理:
比如我现在动态分配了3块内存空间,每个内存块对应信息如下。
内存块1:
内存地址-94 00 00 20(十六进制),转换成高位在前就是0x20000094
内存大小-0a 00,换算成10进制就是10个数据,代表缓存区大小是10个字节
内存ID-01 00,每个内存块ID都不同,自动递增
缓存区-0x20000094这个地址存储的数据,我程序初始化为全是1。
内存块2:
内存地址- 8c 00 00 20 (十六进制),转换成高位在前就是0x2000008c
内存大小- 08 00,换算成10进制就是8个数据,代表缓存区大小是8个字节
内存ID-02 00,每个内存块ID都不同,自动递增
缓存区-0x2000008c这个地址存储的数据,我程序初始化为全是2。
内存块3:
内存地址- 78 00 00 20 (十六进制),转换成高位在前就是0x20000078
内存大小- 14 00,换算成10进制就是20个数据,代表缓存区大小是20个字节
内存ID-03 00,每个内存块ID都不同,自动递增
缓存区-0x20000078这个地址存储的数据,我程序初始化为全是3。
最终内存池里的结构就是这样的。
Ok,这个时候我调用内存释放函数mem_free(2),把内存块2的空间释放掉。
释放完以后,内存池的存储结构就成下图了。

从图中可以看出,内存块2的内存表格信息和缓存区的数据都被内存块3替代了。
所以mem_free(2)函数实现步骤大概如下:
第一步:先通过ID找到要释放的内存块表格信息,表格信息里有缓存区的地址。
第二步:通过内存块2的信息可以计算出内存块3的表格地址。
第三步:把内存块3的缓存区数据迁移并覆盖到内存块2的缓存区 (也就是8个字节)。
第四步:内存块3往内存空间高字节地址迁移8个字节(内存块2缓存区大小)后,会多8个字节数据出来,值为3,把这8个字节数据清零。
第五步:把内存块2的表格信息替换成内存块3的表格信息
第六步:更新内存块3表格信息里的缓存区地址改成最新的地址。
第六步:最后把原来存储内存块3表格信息地址的数据清掉,因为内存块3表格信息此时已在内存块2表格的位置。
这个步骤,估计大家已经看晕了。
这个不是写给你现在看的,想要理解这个代码,最好就是用串口把数据打印出来,一用看数据一边用st-link仿真分析程序。
如果没思路,再看我这个流程。
实现思路最重要,有这个思路完全可以自己写代码去实现。
至此,整个内存管理分析分享到此结束。
这个内存管理的代码还是需要进一步优化才能真正用在项目上。
比如说:
1.现在动态分配内存是返回内存块ID,实际最好返回分配出来的缓存区地址。
2.释放内存是传递内存块ID,实际最好传递缓存区地址。
3.分配和释放内存前要进入临界
这个就靠大家自己去优化了,我会把优化好的版本共享给我们的学员。
如果要这个版本的源代码,可以找无际拿。
最后,目前我发现这个内存管理代码唯一不足的地方就是每分配一块内存都要额外增加8个字节来存储内存块表格信息。
源代码是12个字节,被我干掉了4个,实际如果单次分配不超过256个字节,6个字节就够用)。
