4096点击型号即可查看芯片规格书
8226点击型号即可查看芯片规格书
PQ208点击型号即可查看芯片规格书
605点击型号即可查看芯片规格书
介绍
Spartan-II 2.5V现场可编程门阵列系列以极低的价格为用户提供了高性能、丰富的逻辑资源和丰富的功能集。这个六人家庭提供的系统门密度从15000到200000不等。系统性能支持高达200兆赫。
斯巴达II设备通过将先进的工艺技术与流线型的基于Virtex的架构相结合,提供了比其他FPGAs更多的门、I/O和每美元的功能。功能包括块RAM(至56K位)、分布式RAM(至75264位)、16个可选I/O标准和4个DLL。快速、可预测的互连意味着连续的设计迭代继续满足时序要求。
斯巴达II家族是一个优于掩模编程ASIC的替代品。fpga避免了传统asic的初始成本、冗长的开发周期和固有的风险。此外,fpga可编程性允许在现场进行设计升级,无需更换硬件(asic不可能)。
特征
第二代ASIC替换技术
- 密度高达5292个逻辑单元
- 基于virtex架构的精简功能
- 无限可重编程性
- 非常低的成本
- 先进的0.18微米工艺
系统级功能-SelectRAM+分层内存:
·16位/lut分布式ram
·可配置4K位块RAM
·与外部RAM的快速接口
- 完全符合PCI
- 低功耗分段路由体系结构
- 验证/观察的完全可读性
- 高速运算专用进位逻辑
- 有效的乘数支持
- 宽输入函数的级联链
- 具有启用、设置、复位功能的大量寄存器/锁存器
- 四个用于高级时钟控制的专用dll
- 四个主低偏斜全局时钟分布网
- ieee 1149.1兼容边界扫描逻辑
多功能I/O和封装
- PB免费套餐选项
- 各种密度的低成本包装
- 公共包中的族足迹兼容性
- 16高性能接口标准
- 热插拔紧凑型PCI友好型
- 零保持时间简化了系统计时
充分支持强大的Xilinx开发系统——基础ISE系列:完全集成的软件
- 联盟系列:用于第三方工具
- 全自动映射、放置和路由
概述
Spartan II系列FPGas具有规则、灵活、可编程的可配置逻辑块(CLB)体系结构,周围环绕着可编程输入/输出块(IOB)。有四个延迟锁定环(dll),在模具的每个角落都有一个。两列块RAM位于模具的对侧,在CLB和IOB列之间。这些功能元素通过多功能路由通道的强大层次结构互连。
Spartan II FPGas是通过将配置数据加载到内部静态存储单元来定制的。使用这种方法可以无限次地重新编程。这些单元中的存储值决定了逻辑功能和在fpga中实现的互连。配置数据可以从外部串行prom(主串行模式)读取,也可以以从串行、从并行或边界扫描模式写入fpga。
Spartan II FPGAs通常用于高容量应用,快速可编程解决方案的多功能性增加了好处。斯巴达II型FPGAs是缩短产品开发周期的理想选择,同时为大批量生产提供了一个经济高效的解决方案。
斯巴达ii型fpgas通过先进的架构和半导体技术实现了高性能、低成本的运行。斯巴达II设备提供高达200兆赫的系统时钟速率。斯巴达II FPGAs在保持领先性能的同时,提供最具成本效益的解决方案。除了大容量可编程逻辑解决方案的传统优势外,Spartan II FPGas还提供了片上同步单端口和双端口RAM(块和分布式形式)、动态链接库时钟驱动器、所有触发器上的可编程设置和复位、快速进位逻辑和许多其他功能。
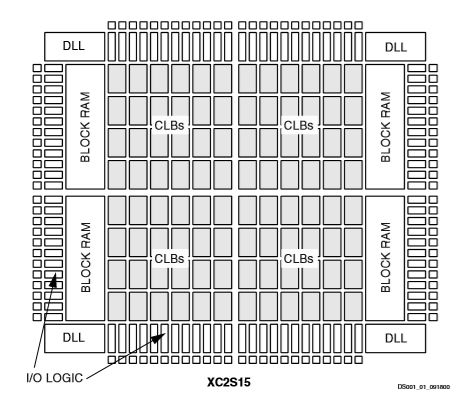
建筑描述
斯巴达II阵
斯巴达II用户可编程门阵列,如图1所示,由五个主要可配置元件组成:
IOB提供封装引脚和内部逻辑之间的接口
CLB提供了构建大多数逻辑的功能元素
每个4096位的专用块RAM存储器
用于时钟分布延迟补偿和时钟域控制的时钟dll
多功能多层互连结构
CLB形成了中心逻辑结构,可以方便地访问所有支持和路由结构。IOB位于所有逻辑和内存元素的周围,便于在芯片上和芯片外快速路由信号。
存储在静态存储单元中的值控制所有可配置的逻辑元素和互连资源。这些值在通电时加载到内存单元中,如果需要更改设备的功能,可以重新加载。
以下各节将详细讨论这些元素。
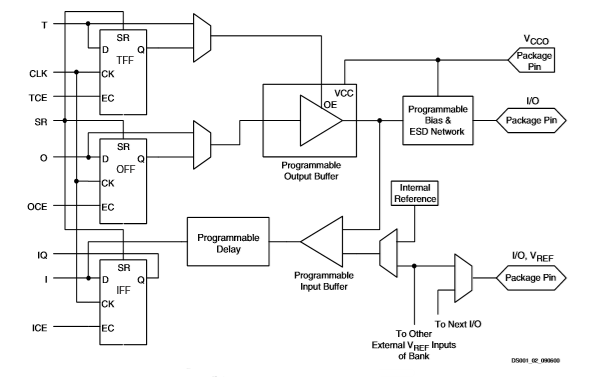
输入/输出块
Spartan II IOB具有支持多种I/O信令标准的输入和输出功能。这些高速输入和输出能够支持各种最先进的存储器和总线接口。
设备上可用的最大用户I/O和每个设备/包组合可用的用户I/O数量。四个全局时钟管脚在不用作全局时钟管脚时可用作附加用户I/O。这些管脚不包括在用户I/O计数中。
配置前上拉电阻器的激活由配置模式管脚全局控制。如果上拉电阻器未激活,则所有触针都将浮动。因此,外部上拉或下拉电阻器必须在配置前设置在需要处于良好定义逻辑级别的管脚上。
所有衬垫都受到保护,防止静电放电(ESD)和过电压瞬变造成损坏。提供两种形式的过电压保护,一种允许5V符合性,另一种不符合。对于5V符合性,当输出上升到约6.5V时,与接地连接的齐纳型结构打开。当不需要5V符合性时,可将常规钳位二极管连接到输出电源电压VCCO。过电压保护的类型可以为每个焊盘单独选择。
所有Spartan II IOB都支持IEEE1149.1兼容边界扫描测试。
输入路径
斯巴达II IOB输入路径中的缓冲器将输入信号直接路由到内部逻辑或通过可选的输入触发器。
在这个触发器的d输入端有一个可选的延迟元件,消除了pad到pad的保持时间。延迟与fpga的内部时钟分配延迟相匹配,使用时确保pad-pad保持时间为零。
每个输入缓冲器可以配置为符合支持的任何低压信令标准。在其中一些标准中,输入缓冲器利用用户提供的阈值电压vref。提供VREF的需要对标准之间的使用施加了限制。。输入输出银行业务
每个输入端都有可选的上拉和下拉电阻器,供配置后使用。
输出路径
输出路径包括三态输出缓冲器,其将输出信号驱动到焊盘上。输出信号可以直接从内部逻辑或通过可选的iob输出触发器路由到缓冲器。
输出的三态控制也可以直接从内部逻辑或通过提供同步启用和禁用的翻转来路由。
每个输出驱动器都可以单独编程,用于各种低压信号标准。每个输出缓冲区可以源高达24毫安,汇高达48毫安。驱动强度和回转率控制使总线瞬态最小化。
在大多数信令标准中,输出的高电压取决于外部提供的vcco电压。供应VCCO的需要对标准的使用施加了限制。看。输入输出银行业务
一个可选的弱保持电路连接到每个输出。当被选中时,电路监测焊盘上的电压,并弱驱动引脚高或低以匹配输入信号。如果管脚连接到一个多源信号,如果所有驱动器都被禁用,弱保持器会将信号保持在其最后状态。以这种方式维护一个有效的逻辑级别有助于消除总线抖动。
由于弱保持电路使用iob输入缓冲器来监测输入电平,因此如果信令标准需要,则必须提供适当的vref电压。提供的电压必须符合I/O银行规则。
输入输出银行业务
上面描述的一些I/O标准需要VCCO和/或VREF电压。这些电压从外部连接到设备管脚,这些管脚服务于一组称为电池组的IOB。因此,在给定的银行中可以组合哪些I/O标准存在限制。
八个I/O组是将FPGA的每个边缘分成两个组的结果。每家银行都有多个VCCO管脚,必须连接到相同的电压。电压由使用中的输出标准决定一些输入标准需要用户提供的阈值电压vref。在这种情况下,某些用户I/O引脚会自动配置为VREF电压的输入。银行中大约六分之一的I/O管脚承担这个角色。
一个组内的VREF引脚在内部互连,因此每个组内只能使用一个VREF电压。然而,组中的所有VREF管脚必须连接到外部电压源才能正常工作。
在一个组中,需要vref的输入可以与那些不需要vref的输入混合,但是在一个组中只能使用一个vref电压。使用vref的输入缓冲区不允许5v电压。LVTTL、LVCMOS2和PCI具有5V的耐受性。每个组的VCCO和VREF管脚出现在设备管脚输出表中。
在给定的封装中,vref和vcco管脚的数量可以根据设备的大小而变化。在较大的设备中,更多的I/O管脚转换为VREF管脚。由于这些都是用于较小设备的vref管脚的超集,因此可以设计允许迁移到较大设备的pcb。预期最大设备的所有VREF引脚必须连接到VREF电压,而不是用于I/O。
可配置逻辑模块
斯巴达II CLB的基本组成部分是逻辑单元(LC)。lc包括4输入函数发生器、进位逻辑和存储元件。每个lc中的函数发生器输出驱动触发器的clb输出和d输入。每个斯巴达II CLB包含四个LCS,组织成两个相似的切片
除了四个基本LCS之外,斯巴达II CLB还包含结合函数生成器以提供五个或六个输入的函数的逻辑。
查找表
斯巴达II函数生成器被实现为4输入查找表(lut)。除了作为函数生成器运行外,每个lut还可以提供16 x 1位同步ram。此外,片内的两个lut可以组合以创建16 x 2位或32 x 1位同步ram,或16 x 1位双端口同步ram。
spartan ii lut还可以提供16位移位寄存器,非常适合捕获高速或突发模式数据。此模式也可用于在数字信号处理等应用中存储数据。
存储元件
Spartan II片中的存储元件可以配置为边缘触发D型触发器或电平敏感锁存器。d输入可以由片内的函数生成器驱动,也可以直接由片输入驱动,绕过函数生成器。
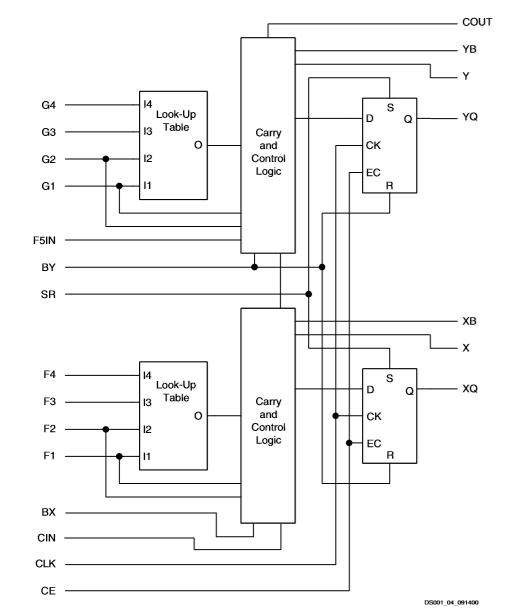
算术逻辑
专用进位逻辑为高速运算功能提供快速运算进位能力。斯巴达II CLB支持两个独立的传送链,每片一个。进位链的高度是每CLB两位。
算术逻辑包括一个异或门,该异或门允许在lc中实现1位全加器。此外,专用与门提高了乘法器实现的效率。
专用进位路径也可用于级联函数生成器以实现宽逻辑函数。
三态缓冲器
每个Spartan II CLB包含两个可驱动片上总线的三态驱动程序(BUFTS)。每个斯巴达II BUFT都有一个独立的3态控制引脚和一个独立的输入引脚。专用路由
块存储器
Spartan II FPGas包含几个大型块RAM存储器。它们补充了分布式ram查找表(lut),后者提供在clb中实现的浅内存结构。
块ram内存块按列组织。所有斯巴达II设备都包含两个这样的柱,每个垂直边缘一个。这些柱子延伸了芯片的整个高度。每个内存块有四个CLB高,因此,斯巴达II设备八个CLB高将包含每列两个内存块,总共四个块。
可编程路由矩阵
它是最长的延迟路径,限制了任何最坏情况下的设计速度。因此,Spartan II路由体系结构及其位置和路由软件在单个优化过程中定义。这种联合优化最小化了长路径延迟,从而获得最佳的系统性能。
联合优化还减少了设计编译时间,因为该体系结构是软件友好的。由于缩短了设计迭代时间,相应地减少了设计周期。
本地路由
lut、触发器和通用路由矩阵(grm)之间的互连
内部CLB反馈路径,为同一CLB内的LUT提供高速连接,以最小的路由延迟将它们链接在一起
在水平相邻CLB之间提供高速连接的直接路径,消除GRM的延迟
通用路由
大多数Spartan II信号在通用路由上路由,因此,大多数互连资源与此级别的路由层次结构相关联。常规路由资源位于与行和列clb关联的水平和垂直路由通道中。通用路由资源如下所示。
与每个CLB相邻的是一个通用路由矩阵(GRM)。GRM是水平和垂直路由资源连接的交换矩阵,也是CLB获得通用路由访问权的手段。
24条单线在四个方向上将GRM信号路由到相邻的GRM。
96条缓冲十六进制线路在四个方向中的每一个方向将GRM信号路由到六个街区以外的其他GRM。以交错模式组织,十六进制线只能在其端点处驱动。十六进制线信号可以在端点或中点(距离源三个块)访问。三分之一的十六进制是双向的,其余的是单向的。
12根长线路是缓冲的双向电线,可快速高效地在设备上分配信号。垂直的长线跨越设备的整个高度,水平的则跨越设备的整个宽度。
输入输出路由
斯巴达II设备的外围有额外的路由资源,这些资源形成了CLB阵列和IOB之间的接口。这种额外的布线称为Versaring,有利于管脚交换和管脚锁定,这样逻辑重新设计就可以适应现有的PCB布局。上市时间缩短了,因为pcb和其他系统组件可以在逻辑设计仍在进行时制造。
专用路由
某些类型的信号需要专用的路由资源来最大限度地提高性能。在Spartan II体系结构中,为两类信号提供专用的路由资源。
为片上3态总线提供水平路由资源。每个CLB行提供四条可分割的总线,允许一行中有多条总线
专用水平母线的BUFT连接
每个CLB有两个专用网络将进位信号垂直传播到相邻的CLB。
全局路由
全局路由资源在整个设备中以非常高的扇出分布时钟和其他信号。Spartan II设备包括两层全局路由资源,称为主要和次要全局路由资源。
主要的全局路由资源是四个具有专用输入管脚的专用全局网络,其设计用于以最小的偏差分发高扇出时钟信号。每个全局时钟网络可以驱动所有CLB、IOB和块RAM时钟管脚。主全局网只能由全局缓冲区驱动。有四个全局缓冲区,每个全局网络一个。
第二全局路由资源包括24条主干线,12条穿过芯片顶部,12条穿过底部。从这些线路中,每列最多可以通过列中的12条长线分布12个唯一信号。这些辅助资源比主资源更灵活,因为它们不限于仅路由到时钟管脚。
时钟分布
Spartan II系列通过上述主要全局路由资源提供高速、低斜时钟分布。
提供四个全局缓冲区,两个位于设备的上中心,两个位于设备的下中心。这些驱动四个主要的全局网络,反过来驱动任何时钟管脚。
提供了四个专用的时钟板,一个与每个全局缓冲区相邻。全局缓冲区的输入可以从这些焊盘中选择,也可以从通用路由中的信号中选择。全局时钟管脚没有用于内部弱上拉电阻器的选项。
延迟锁定循环(dll)
与每个全局时钟输入缓冲区相关联的是一个全数字延迟锁定环(dll),它可以消除整个设备中时钟输入板和内部时钟输入管脚之间的偏差。每个dll可以驱动两个全局时钟网络。动态链接库监视输入时钟和分布式时钟,并自动调整时钟延迟元素。引入额外的延迟,使得时钟边缘在到达输入端后正好到达一个时钟周期的内部触发器。该闭环系统通过确保时钟边缘与到达输入端的时钟边缘同步到达内部触发器,有效地消除了时钟分布延迟。
除了消除时钟分布延迟之外,dll还提供了对多个时钟域的高级控制。动态链接库提供源时钟的四个正交相位,可以使时钟加倍,或将时钟除以1.5、2、2.5、3、4、5、8或16。它有六个输出。
动态链接库还用作时钟镜像。通过将dll的输出从片外驱动,然后再重新打开,dll可用于在多个spartan ii设备之间消除板级时钟。
为了保证系统时钟在配置后的fpga启动前正常工作,dll可以将配置过程的完成延迟到锁定后。
边界扫描
斯巴达II设备支持IEEE标准1149.1中规定的所有强制性边界扫描指令。提供了一个测试访问端口(tap)和寄存器,用于实现extest、sample/preload和bypass指令。tap还支持两个用户代码指令和内部扫描链。
全球时钟分配网
抽头使用专用封装引脚,始终使用LVTTL工作。要使TDO使用LVTTL工作,气缸组2的VCCO必须为3.3V。否则,TDO将在地面和VCCO之间切换到轨道。
边界扫描操作独立于各个iob配置,不受包类型的影响。所有IOB,包括未绑定的IOB,都被视为一个扫描链中独立的3态双向管脚。配置后保持双向测试能力有助于外部互连的测试。
通过将内部信号连接到未绑定或未使用的iob,可以在extest期间捕获内部信号。它们还可以连接到定义为单向输入引脚的iob的未使用输出。
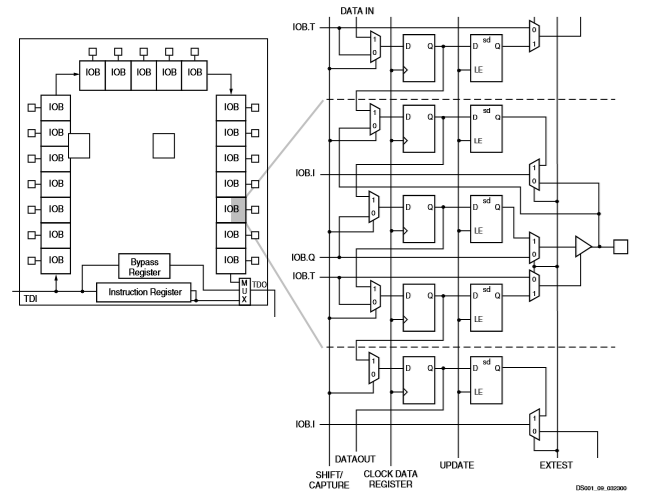
位序列每个iob中的位序列是:in,out,3状态。仅输入管脚仅对边界扫描I/O数据寄存器贡献入位,而仅输出管脚对所有三位都贡献。
从芯片的腔向上视图(如fpga编辑器所示),从右上角开始,边界扫描数据寄存器位的顺序。spartan ii系列设备的bsdl(边界扫描描述语言)文件可在xilinx网站的文件下载区域中找到。
开发系统
斯巴达II FPGA由Xilinx基金会和联盟CAE工具支持。斯巴达II设计的基本方法包括三个相互关联的步骤:设计输入、实现和验证。行业标准工具用于设计输入和模拟(例如Synopsys的FPGA Express),而Xilinx提供专用的体系结构专用工具用于实现。
xilinx开发系统集成在xilinx design manager软件下,为设计人员提供了一个通用的用户界面,而不管他们选择何种输入和验证工具。该软件通过下拉菜单和在线帮助简化了实现选项的选择。
可以通过软件访问从示意图捕获到布局和路由(PAR)的应用程序。程序命令序列在执行之前生成,并存储以备文档使用。
几个先进的软件功能有助于斯巴达II的设计。例如,相对放置的宏(RPM)是基于原理图的宏,具有相对位置约束以指导其放置。它们有助于确保公共功能的最佳实现。
对于hdl设计入口,xilinx的fpga开发系统提供了多个综合设计环境的接口。
一个标准的接口文件规范,电子设计交换格式(edif),简化了进出开发系统的文件传输。
斯巴达II FPGAs由标准功能的统一库支持。这个库包含400多个原语和宏,从2输入和门到16位累加器,包括算术函数、比较器、计数器、数据寄存器、解码器、编码器、I/O函数、锁存器、布尔函数、多路复用器、移位寄存器和桶移位器。
库的“软宏”部分包含公共逻辑函数的详细描述,但不包含任何分区或位置信息。因此,这些宏的性能取决于实现过程中获得的分区和位置。
另一方面,rpm包含预先确定的分区和放置信息,这些信息允许这些功能的最佳实现。用户可以基于标准库中的宏和原语创建自己的软宏或RPM库。
设计环境支持层次化的设计条目,其中高级示意图包含主要功能块,而低级示意图定义这些块中的逻辑。这些分层设计元素由实现工具自动组合。不同的设计输入工具可以组合在一个分层设计中,从而允许对设计的每个部分使用最方便的输入方法。
设计实现
位置和路径工具(PAR)自动提供在本节中描述的实现流程。分区器采用edif netlist进行设计,并将逻辑映射到fpga的架构资源中(例如,clbs和iobs)。然后,放置器根据这些块的互连和所需性能来确定这些块的最佳位置。最后,路由器将块互连。
PAR算法支持大多数设计的完全自动实现。然而,对于要求很高的应用程序,用户可以对过程进行不同程度的控制。用户分区、位置和路由信息可以在设计输入过程中选择性地指定。高度结构化设计的实现可以从基本的平面规划中受益匪浅。
实施软件结合了Timing Wizard®定时驱动布局和路由。设计人员在设计输入期间指定沿整个路径的计时要求。PAR中的定时路径分析例程然后识别这些用户指定的要求并适应它们。
时序要求以与系统要求直接相关的形式输入在原理图上,例如目标时钟频率或两个寄存器之间的最大允许延迟。这样,沿着整个信号路径的系统的总体性能将根据用户生成的规范自动调整。不需要为单个网络提供特定的定时信息。
设计验证
除了传统的软件仿真外,fpga用户还可以使用电路内调试技术。由于xilinx设备是无限可重编程的,因此可以实时验证设计,而无需大量的软件模拟矢量集。
开发系统支持软件仿真和电路内调试技术。为了进行仿真,系统从设计数据库中提取布局后的时序信息,并将这些信息重新注释到netlist中,以供模拟器使用。或者,用户可以使用静态定时分析器验证设计的定时关键部分。
为了进行电路内调试,开发系统包括下载和回读电缆,该电缆将目标系统中的fpga连接到pc或工作站。在将设计下载到fpga中之后,设计者可以单步执行逻辑,读取触发器的内容,从而观察内部的逻辑状态。简单的修改可以在几分钟内下载到系统中。
配置
配置是将xilinx开发软件生成的设计比特流加载到fpga内部配置存储器中的过程。斯巴达II设备既支持串行配置,使用主/从串行和JTAG模式,也支持字节宽配置,使用从并行模式。
配置文件
斯巴达II设备通过顺序加载连接到配置文件中的数据帧来配置。表7显示斯巴达II设备需要多少非易失性存储空间。
需要注意的是,虽然prom通常用于在将配置数据加载到fpga之前存储配置数据,但它并不是必需的。板上或板下已有的各种类型的未充分填充的非易失性存储器(即硬盘、闪存)
配置模式
清除配置内存
设备指示清除配置内存
正在通过将初始值设置为低来进行。此时,用户可以通过保持program或init low来延迟配置,这将导致设备保持在内存清除阶段。请注意,在内存清除期间,双向初始化行正在驱动低逻辑级别。因此,为了避免争用,可以使用一个开放的drain驱动程序来保持init低。
在没有延迟的情况下,设备指示内存
是完全清楚的通过驾驶init高。在这种从低到高的转换中,fpga对其模式管脚进行采样。
加载配置数据
一旦init为high,用户就可以开始将配置数据帧加载到设备中。在分别处理配置模式的章节中讨论了加载配置数据的细节。使用串行模式加载配置数据所需的操作顺序如图13所示。使用从机并行模式加载数据如第18页图18所示。
CRC错误检查
在加载配置数据期间,根据在fpga中计算的crc值检查嵌入在配置文件中的crc值。如果crc值不匹配,则fpga将低启动,以指示发生了帧错误并中止配置。
要重新配置设备,应断言程序pin以重置配置逻辑。再循环电源也会重置配置的fpga。看。清除配置内存
启动
启动序列监督fpga从配置状态到完全用户操作的转换。crc值的匹配,指示配置数据的成功加载,启动序列。
在启动过程中,设备执行四个操作:
1. 完成的断言。done to go high失败可能表示配置数据加载失败。
2. 全球三州网的发布。这将激活分配信号的I/O。其余的I/O保持在高阻抗状态,存在内部弱下拉电阻。
3. 否定全局设置重置(GSR)。这允许所有触发器改变状态。
4. 全局写启用(gwe)的断言。这允许所有ram和触发器改变状态。
默认情况下,这些操作与cclk同步。整个启动程序持续8个周期,称为C0-C7,之后加载的设计完全正常。可以选择这四个操作,通过xilinx开发软件中的设置打开任何cclk循环c1-c6。粗线显示默认设置。
通过在配置选项中将gts、gsr和gwe周期设置为done值来选择sync to done timing。这导致这些信号在完成外部高转换后转换一个时钟周期。
串行模式
有两种串行配置模式:在主串行模式下,fpga通过驱动cclk作为输出来控制配置过程。在从串行模式下,fpga被动地从控制配置过程的外部代理(例如微处理器、cpld或主模式下的第二个fpga)接收cclk作为输入。在这两种模式下,通过每个cclk周期加载一位来配置fpga。每个配置数据字节的msb总是首先写入din pin。
启动波形
加载串行模式配置数据
从串行模式
在从串行模式下,fpga的cclk引脚由外部源驱动,允许从其他逻辑设备(如微处理器)或菊花链配置中配置fpga。图14显示了主串行fpga从prom配置从串行fpga的连接。串行比特流必须在外部生成的cclk的每个上升沿之前的短时间内设置在din输入引脚上。从串行模式下的多个fpga可以通过菊花链从一个源进行配置。在配置了一个fpga之后,下一个设备的数据被路由到dout管脚。豆瓣上升时的变化数据
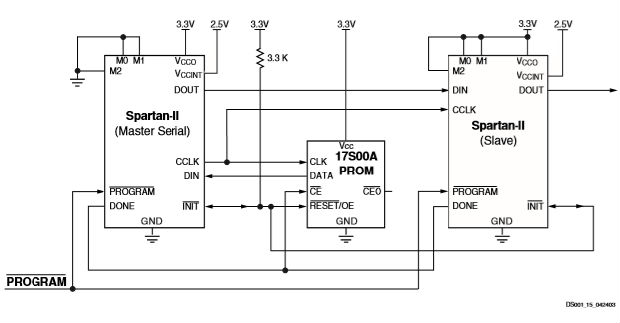
CCLK的边缘。必须延迟配置,直到所有菊花链FPA的初始管脚都高。
串行模式
在主串行模式下,fpga的cclk输出驱动xilinx prom,xilinx prom将配置数据的串行流馈送给fpga的din输入。主串行模式下的斯巴达II设备应按左侧设备所示进行连接。主串行模式由模式引脚上的<00x>选择(m0,m1,m2)。prom复位引脚由init驱动,ce输入由done驱动。该接口与从机串行模式相同,只是使用了一个内部到fpga的振荡器来生成配置时钟(cclk)。可以使用xilinx开发软件中的configrate选项设置从4到60兆赫的任意不同频率。通电时,当加载配置数据的前60个字节时,cclk频率始终为2.5mhz。在配置文件的一部分configrate位加载到fpga中之前,使用该频率,此时,频率将更改为选定的configrate。除非在设计中指定了不同的频率,否则默认配置速率为4 MHz。由内部振荡器产生的cclk信号的周期与指定值的偏差为+45%–30%。
从并行模式
从并行模式是最快的配置选项。字节范围的数据被写入到fpga中。提供了一个忙标志,用于控制时钟频率fccnh在50mhz以上的数据流。
使用从机并行模式的两个Spartan II设备的连接。从并行模式由模式引脚(m0,m1,m2)上的a<011>选择。
如果使用.bit、.rbt或非交换十六进制格式的配置文件进行并行编程,则最有效的位(即每个配置字节的最左边的位,如文本编辑器中所示)必须路由到fpga上的d0输入。
未显示代理控制配置。通常,处理器、微控制器或cpld控制从机并行接口。控制代理提供字节范围配置数据、CCLK、芯片选择(CS)信号和写入信号(写入)。如果fpga断言busy(高),则必须保持数据直到busy变低。
配置后,从机并行端口(d0-d7)的管脚可以用作额外的用户I/O。或者,可以保留该端口以允许高速8位读取-
回来。然后可以通过取消断言写入来读取数据。
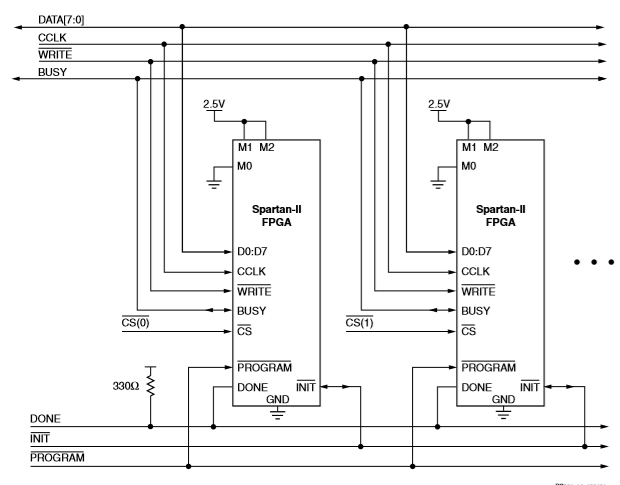
从机并联配置电路图
多个斯巴达II型FPA可采用从机并联模式进行配置,并进行模拟启动-
天真地。要以这种方式配置多个设备,请将所有设备的单个cclk、数据、写和忙管脚并联起来。通过依次断言每个设备的cs pin并写入适当的数据,分别加载各个设备。sync to done启动定时用于确保在加载完所有的fpgas之前启动序列不会开始
对于本例,用户在整个写操作序列中保持write和cs low。注意
在连续的cclk上断言cs时,write必须保持断言或取消断言。否则将启动中止,如下一节所述。
1. 将数据驱动到d0-d7上。请注意,为了避免争用,在cs较低时不应启用数据源
写得很高。同样地,当write是high时,no
应断言多个设备的CS。
2. 在cclk的上升沿上:如果busy很低,则在这个时钟上接受数据。如果忙是高(从以前的写入),则不接受数据。相反,在busy变低后的第一个时钟上会出现接受,并且数据必须保持到发生这种情况为止。
3. 重复步骤1和2,直到发送完所有数据。
4. 取消断言CS并写入。
如果cclk比fccnh慢,则fpga永远不会断言
忙碌的。在这种情况下,上述握手是不必要的,并且数据可以简单地输入到每个cclk的fpga中。
边界扫描模式
在边界扫描模式下,不需要非指定管脚,配置完全通过ieee 1149.1测试访问端口完成。
通过TAP的配置使用特殊的CFG指令。此指令允许将TDI上的数据输入转换为内部配置总线的数据包。
通过边界扫描端口配置fpga需要以下步骤。
1. 将cfg_-in指令加载到边界扫描指令寄存器(ir)中
2. 进入移位dr(sdr)状态
3. 将标准配置位流转换为TDI
4. 返回运行测试空闲(RTI)
5. 将jstart指令加载到ir中
6. 进入SDR状态
7. 通过序列时钟TCK(长度可编程)
8. 返回RTI
始终可以通过点击进行配置和回读。边界扫描模式简单地锁定了其他模式。边界扫描模式由模式管脚(m0,m1,m2)上的a<10x>选择。
存储在Spartan II配置存储器中的配置数据可以被读回进行验证。除了配置数据之外,还可以读取所有触发器/锁存器、lut ram和块ram的内容。此功能用于实时调试。
有关更多详细信息,请参阅xapp176,spartan ii fpga系列配置和回读。
使用延迟锁定循环
spartan ii的fpga家族提供多达四个全数字专用片上延迟锁定环(dll)电路,这些电路提供零传播延迟、分布在整个器件中的输出时钟信号之间的低时钟偏差以及先进的时钟域控制。这些专用的dlls可以用来实现一些改进和简化系统级设计的电路。
介绍
随着fpgas尺寸的增大,片上时钟的质量分配变得越来越重要。时钟偏差和时钟延迟会影响设备性能,在大型设备中,使用传统的时钟树来管理时钟偏差和时钟延迟的任务变得更加困难。Spartan II系列设备通过提供多达四个全数字专用片上延迟锁定环(DLL)电路来解决这个潜在问题,这些电路在分布在整个设备上的输出时钟信号之间提供零传播延迟和低时钟偏差。
每个dll可以在设备内驱动最多两个全局时钟路由网络。全球时钟分布网络最小化了由于负载差异造成的时钟偏差。通过监视dll输出时钟的样本,dll可以补偿路由网络上的延迟,有效地消除从外部输入端口到设备内单个时钟负载的延迟。
除了对用户源时钟提供零延迟外,dll还可以提供源时钟的多个相位。dll还可以充当时钟倍增器,或者它可以将用户源时钟除以16。
时钟乘法为设计者提供了许多设计方案。例如,由dll倍增的50mhz源时钟可以驱动在100mhz下工作的fpga设计。这种技术可以简化电路板的设计,因为电路板上的时钟路径不再分布这样的高速信号。倍增时钟还为设计者提供了时域复用的选择,每个时钟周期使用一个电路两次,占用的面积小于同一电路的两个副本。中的两个dll可以串联以将有效时钟倍增因子增加到4。
dll还可以充当时钟镜像。通过驱动从芯片输出的dll,然后再次输入,dll可以用来在多个设备之间消除板级时钟的偏差。
为了保证系统时钟在设备“唤醒”之前建立,dll可以延迟设备配置过程的完成,直到dll实现锁定为止。
利用动态链接库(dll)消除片上时钟延迟,可以大大简化和改进涉及高扇出、高性能时钟的系统级设计。
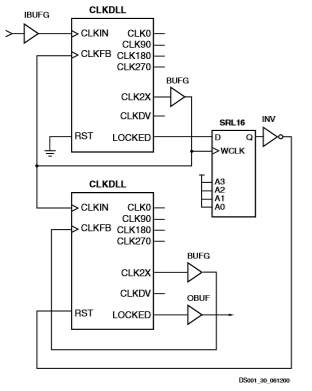
clkdll基元pin描述
库clkdll原语提供了使用dll实现更复杂应用程序时所需的一整套dll功能的访问。
源时钟输入-clkin
clkin pin向dll提供用户源时钟(dll运行时的时钟信号)。clkin频率必须在数据表中指定的范围内。从另一个clkdll或一个全局时钟输入缓冲区(ibufg)驱动的全局时钟缓冲区(bufg)必须提供该时钟信号。
反馈时钟输入-CLKFB
动态链接库需要一个参考或反馈信号来提供延迟补偿输出。只将clk0或clk2x dll输出连接到反馈时钟输入(clkfb)管脚,以向dll提供必要的反馈。反馈时钟输入也可以通过以下引脚之一提供。
IBUFG-全局时钟输入板
如果ibufg来源于clkfb pin,则以下特殊规则适用。
1. 外部输入端口必须提供驱动ibufg i管脚的信号。
2. 如果CLK0和CLK2X输出都驱动芯片外设备,则CLK2X输出必须反馈给设备。
3. 这个信号必须直接驱动obufs而不是其他东西。
这些规则使软件能够确定哪个dll时钟输出源clkfb pin。
重置输入-重新设置
当复位引脚重新设置激活时,锁定信号在四个源时钟周期内停用。RST引脚(高电平激活)必须连接到动态信号或接地。当dll延迟抽头重置为零时,dll时钟输出管脚可能会出现故障。RST引脚的激活也会严重影响时钟输出引脚的占空比。此外,dll的输出时钟不再互相抵消。出于这些原因,除非重新配置设备或更改输入频率,否则很少使用重置管脚。
2X时钟输出-CLK2X
输出引脚clk2x提供一个倍频时钟,具有自动50/50占空比校正功能。在CLKDLL实现锁定之前,CLK2X输出显示为具有25/75占空比的1X版本的输入时钟。此行为允许dll锁定相对于源时钟的正确边缘。此pin在clkdllhf原语上不可用。
时钟分频输出-CLKDV
时钟分频输出管脚clkdv提供源时钟的低频版本。clkdv_u divide属性控制clkdv,使得源时钟除以n,其中n是1.5、2、2.5、3、4、5、8或16。
此功能提供自动占空比校正,以便CLKDV输出引脚始终具有50/50占空比。
1X时钟输出-CLK[0 90 180 270]
1X时钟输出引脚clk0表示源时钟(clkin)信号的延迟补偿版本。clkdll原语提供clk0信号的三个相移版本,而clkdllhf仅提供180个相移版本。
动态链接库在所有1X时钟输出上提供占空比校正,使所有1X时钟输出默认具有50/50占空比。占空比校正特性
(默认情况下为true)控制此功能。要停用dll占空比校正,请将占空比校正=false属性附加到
DLL符号。当占空比校正停用时,输出时钟具有与源时钟相同的占空比。
dll时钟输出可以驱动obuf、bufg,也可以直接路由到目标时钟管脚。dll时钟输出只能驱动位于同一边缘(顶部或底部)的bufgs。
锁定输出-锁定
为了实现锁,dll可能需要采样几千个时钟周期。dll锁定后,锁定信号激活。数据表的dll计时参数部分提供锁定时间的估计值。
为了保证在设备“唤醒”之前建立系统时钟,dll可以将设备配置过程的完成延迟到dll锁定之后。startup_wait属性激活此功能。
在锁定信号激活之前,dll输出时钟无效,可能会出现故障、尖峰或其他虚假移动。尤其是CLK2X输出将显示为具有25/75占空比的1X时钟。
dll属性
属性提供对Spartan II系列DLL功能(例如,时钟分割和占空比校正)的访问。
占空比校正特性
1X时钟输出CLK0、CLK90、CLK180和CLK270使用占空比校正默认值,显示50/50占空比。占空比校正属性(默认为true)控制此功能。要停用1X时钟输出的DLL占空比校正,请附加占空比校正=对
DLL符号。当占空比校正停用时,输出时钟具有与源时钟相同的占空比。
时钟分割属性
clkdv_divide属性指定clkdv管脚上的信号如何相对于clk0管脚进行频率划分。此属性允许的值为1.5、2、2.5、3、4、5、8或16;默认值为2。
启动延迟属性
此属性startup_wait的值为true或false(默认值)。如果为true,则设备配置完成信号将一直等到dll锁定,然后变为高。
dll位置约束
dll的分布使得设备的每个角落都有一个dll。附加到具有数字标识符0、1、2或3的dll符号的位置约束loc控制dll位置。图26显示了四个dll及其对应的时钟资源的方向。
loc属性使用以下形式。
设计因素
使用以下设计注意事项可以避免陷阱,并提高使用xilinx设备进行设计的成功率。
输入时钟
dll的输出时钟信号,本质上是输入时钟信号的延迟版本,反映了输出波形中输入时钟的任何不稳定性。因此,dll输入时钟的质量直接关系到dll生成的输出时钟波形的质量。dll输入时钟要求在数据表中指定。
在大多数系统中,晶体振荡器产生系统时钟。动态链接库可用于任何商用石英晶体振荡器。例如,大多数晶体振荡器产生频率公差为100ppm的输出波形,这意味着时钟周期的变化为0.01%。动态链接库在输入波形上可靠地工作,其频率漂移高达1纳秒,超过了工业上支持任何晶体振荡器所需的数量级。然而,周期间抖动必须保持在低频小于300ps,高频小于150ps。
输入时钟变化
改变输入时钟的周期超过最大漂移量需要手动重置clkdll。未能重置dll将产生不可靠的锁定信号和输出时钟。
可以在对dll影响不大的情况下停止输入时钟。停止时钟的时间应限制在100微秒以下,以使设备冷却到最低限度。时钟应在低相位期间停止,恢复时应看到全高周期。在这段时间内,锁定将保持在高位,并在时钟恢复时保持高位。
当时钟停止时,在刷新延迟线时,仍会观察到一到四个时钟。当时钟重新启动时,由于延迟线已满,一到四个时钟将不观察输出时钟。最常见的情况是两三个时钟。
以类似的方式,输入时钟的相移也是可能的。相移将在原始移位后传播到输出1到4个时钟,不会中断clkdll控制。
输出时钟
正如前面在dll pin描述中提到的,一些限制适用于输出pin的连接。dll时钟输出可以驱动obuf、全局时钟缓冲bufg,也可以直接路由到目标时钟管脚。dll时钟输出可以驱动的唯一bufg是位于设备同一边缘(顶部或底部)的两个bufg。
在锁定信号激活之前,不要使用dll输出时钟信号。在激活锁定信号之前,dll输出时钟无效,可能会出现故障、尖峰或其他虚假移动。
有用的应用示例
斯巴达II动态链接库可以用于各种创造性和有用的应用程序。下面的例子展示了一些更常见的应用程序。
使用块RAM功能
Spartan II FPGA系列提供专用的片上块,真正的双读/写端口同步RAM,带有4096个存储单元。块ram存储器的每个端口可以独立地配置为读/写端口、读端口和写端口,并且可以配置为特定的数据宽度。块ram存储器提供了新的功能,使fpga设计者能够简化设计。
工作模式
块RAM存储器支持两种操作模式。
通读
回写
读取(一个时钟边缘)
读取地址注册在读取端口时钟边缘,数据在RAM访问时间之后出现在输出端。一些存储器可能会将锁存器/寄存器放在输出端,这取决于是否希望与设置时间相比有更快的时钟输出。这通常被认为是较低的解决方案,因为它将读取操作更改为异步功能,并且在读取脉冲时钟的生成期间可能丢失地址/控制线转换。
回写(单时钟边缘)
写入地址注册在写入端口时钟边缘,数据输入写入内存并镜像到写入端口输入。
块RAM特性
1. 所有输入都用端口时钟注册,并具有设置到时钟的定时规范。
2. 根据端口的状态,所有输出都具有读写功能。相对于端口时钟的输出在时钟到输出定时规范之后可用。
3. 块ram是真正的sram存储器,没有从地址到输出的组合路径。clbs中的lut单元仍然可以使用此功能。
4. 端口之间完全独立(即时钟、控制、地址、读/写功能和数据宽度),无需仲裁。
5. 写操作只需要一个时钟边缘。
6. 读取操作只需要一个时钟边缘。
输出端口被一个自动定时电路锁定,以保证无故障读取。在端口执行另一个读或写操作之前,输出端口的状态不会改变。
启用en[a b]
启用管脚会影响端口的读、写和重置功能。具有非活动启用管脚的端口将输出管脚保持在以前的状态,并且不将数据写入内存单元。
写入使能WE[A B]
激活write enable pin允许端口写入内存单元。激活时,数据输入总线的内容被写入地址总线指向的地址处的ram,新数据也反映在数据输出总线上。当不活动时,发生读取操作,地址总线引用的存储单元的内容反映在数据输出总线上。
重置RST[A B]
复位引脚强制数据输出总线锁存同步归零。这不会影响RAM的内存单元,也不会干扰另一个端口上的写入操作。
地址总线地址[A B]<:0>
地址总线选择用于读或写的存储单元。端口的宽度决定了该总线所需的宽度,
总线di[a b]中的数据<:0>
总线中的数据提供要写入RAM的新数据值。此总线和端口的宽度相同
数据输出总线do[a b]<:0>
数据输出总线反映由地址总线在最后一个活动时钟边缘引用的存储单元的内容。在写操作期间,数据输出总线反映总线中的数据。这条总线的宽度等于端口的宽度。
每个端口的四个控制管脚(CLK、EN、WE和RST)具有独立的反转控制作为配置选项。
地址映射
每个端口使用与端口宽度相关的寻址方案访问同一组4096个内存单元。以下公式描述了针对特定宽度寻址的物理ram位置(仅当两个端口使用不同的宽高比时才感兴趣)。
开始=([addrport+1]*widthPort)–1
结束=addrport*宽度端口
创建更大的RAM结构
块ram列有专门的路由,允许在最小路由延迟的情况下级联块。与使用普通路由信道相比,这可以实现更宽或更深的ram结构,并且具有更小的定时代价。
位置约束
块RAM实例可以附加loc属性来约束放置。块ram的放置位置独立于clb位置命名约定,允许loc属性轻松地从一个数组传输到另一个数组。
loc属性使用以下形式:
位置=Ramb4 R C#
Ramb4_r0c0是设备左上角的Ramb4位置。
冲突解决
块ram存储器是一种真正的双读/写端口ram,允许同时从两个端口访问同一个存储单元。当一个端口写入给定的内存单元时,另一个端口不能在“时钟到时钟设置”窗口中寻址该内存单元(用于写入或读取)。下面列出端口和内存单元写入冲突解决的详细信息。
如果两个端口同时写入同一存储单元,违反了时钟到时钟设置的要求,则认为存储的数据无效。
如果一个端口试图读取同一内存单元,另一个端口同时写入,违反了时钟到时钟设置要求,则会发生以下情况。
- 写入成功
- 写入端口上的数据准确地反映了写入的数据。
- 读取端口上的数据输出无效。
冲突不会造成任何身体伤害。
单端口定时
数据表中规定了块RAM AC开关特性。块RAM内存最初被禁用。
在clk pin的第一个上升沿,对addr、di、en、we和rst pin进行采样。en引脚高,we引脚低,表示读取操作。do总线包含addr总线指示的内存位置0x00的内容。
在CLK引脚的第二上升沿,再次对ADDR、DI、EN、WR和RST引脚进行采样。en和we引脚高表示写操作。do总线镜像di总线。DI总线被写入内存位置0x0f。
在CLK引脚的第三个上升沿,再次对ADDR、DI、EN、WR和RST引脚进行采样。en引脚高,we引脚低,表示读取操作。do总线包含addr总线指示的内存位置0x7e的内容。
在CLK管脚的第四上升沿,再次对ADDR、DI、EN、WR和RST管脚进行采样。en引脚低表示块ram内存现在被禁用。do总线保留最后一个值。
双端口定时
只有当两个端口的地址相同并且至少有一个端口正在执行写操作时,tbcc才是重要的。当违反时钟到时钟设置参数的写入条件时,该位置的内存内容将无效。当写入-读取条件违反时钟到时钟设置参数时,内存的内容将正确,但读取端口将包含无效数据。在clka的第一个上升沿,内存位置0x00将使用值0xaaaa写入,并镜像到doa总线上。端口B的最后一次操作是对同一内存位置0x00的读取。端口B的DOB总线不随端口A上的新值而改变,并保留上次读取的值。不久之后,端口B执行另一个对内存位置0x00的读取,而DOB总线现在反映了端口A写入的新内存值。
在clka的第二个上升沿,内存位置0x7e用值0x9999写入,并在doa总线上镜像。然后,端口b在不违反tbccs参数的情况下对同一内存位置执行读取操作,并且dob反映由端口a写入的新内存值。
真正的双端口读写块ram存储器的时序图
在CLKA的第三个上升沿,两次写入内存位置0x0F时违反了TBCC参数。DOA和DOB总线反映了DIA和DIB总线的内容,但0x7E处的存储值无效。
在clka的第四上升沿,在存储器位置0x0f执行读取操作,并且doa总线上存在无效数据。端口B还执行对内存位置0x0f的读取操作,并读取无效数据。
在clka的第五上升沿处,执行一个读取操作,该操作不会违反b端口先前写入0x7e的tbccs参数。doa总线反映b端口最近写入的值。
初始化
块ram存储器可以在设备配置序列期间初始化。每个64个十六进制值(总共4096位)的16个初始化属性设置每个RAM的初始化。这些属性如表13所示。任何未显式设置为零的初始化属性。部分初始化字符串用零填充。大于64个十六进制值的初始化字符串生成错误。在vhdl仿真器中使用泛型,在verilog仿真器中使用参数,用初始化值模拟ram
vhdl和synopsys中的初始化
块ram结构可以用vhdl初始化,用于模拟和合成,以包含在edif输出文件中。vhdl代码的模拟使用泛型来通过初始化。synopsys fpga编译器目前不支持泛型。初始化值通过内置的synopsys dc_脚本作为属性附加到ram。translate_off语句停止泛型语句的合成转换。下面的代码演示了使用这些技术的模块。
在verilog和synopsys中初始化
块ram结构可以在verilog中初始化,用于模拟和合成,以包含在edif输出文件中。verilog代码的模拟使用defparam来传递初始化。synopsys的fpga编译器目前不支持defparam。初始化值通过内置的synopsys dc_脚本作为属性附加到ram。translate_off语句停止defparam语句的合成转换。下面的代码演示了使用这些技术的模块。
块内存生成
coregen程序使用块ram特性生成内存结构。该程序输出vhdl或verilog仿真代码模板和edif文件,以包含在设计中。
使用多功能I/O
Spartan II FPGA系列包括一种高度可配置的高性能I/O资源,称为多用途I/O,可支持多种I/O标准。多功能I/O资源是一组强大的功能,包括输出驱动强度、转换速率、输入延迟和保持时间的可编程控制。利用本文档中描述的灵活性和通用I/O特性以及设计考虑因素,可以改进和简化系统级设计。
介绍
随着fpgas在规模和容量上的不断增长,为其设计的更大、更复杂的系统对i/o标准的要求也越来越高。此外,随着系统时钟速度的不断提高,对高性能i/o的需求变得更加重要。虽然芯片到芯片的延迟对整个系统速度的影响越来越大,但随着低压i/o标准的普及,实现所需系统性能的任务变得更加困难。通用I/O是斯巴达II设备革命性的输入/输出资源,它通过提供一种高度可配置、高性能的替代品来解决这个潜在的问题,替代了更传统的可编程设备的I/O资源。Spartan II多功能I/O功能结合了可编程逻辑的灵活性和上市时间优势,以及以前仅适用于ASIC和定制IC的高性能。
每个通用I/O块最多可支持16个I/O标准。支持这样多种i/o标准可以支持从通用标准应用到高速低压存储总线的各种应用。
多功能I/O块还为LVTTL输出缓冲器提供可选的输出驱动强度和可编程的转换速率,以及可选的、可编程的弱上拉、弱下拉或弱“保持器”电路,非常适合用于外部总线应用
每个输入/输出块(iob)包括三个寄存器,每个寄存器用于iob内的输入、输出和三态信号。这些寄存器可选地可配置为d型触发器或电平敏感锁存器。
输入缓冲器有一个可选的延迟元件,用于保证对在iob中注册的输入信号的零保持时间要求。
多功能I/O功能还为输入参考电压(VREF)和输出源电压(VCCO)提供专用资源,以及简化电路板设计的便捷银行系统。
利用多功能i/o特性支持的内置特性和多种i/o标准,可以大大简化和改进系统级设计和板设计。
基本原理
由数字电子行业中最大和最有影响力的公司率先推出的现代总线应用程序,通常采用专门为该应用程序的需要量身定制的新I/O标准。总线I/O标准为其他供应商提供规范,这些供应商创建的产品设计用于与这些应用程序接口。每个标准通常都有自己的电流、电压、I/O缓冲和终端技术规范。
提供可编程逻辑的灵活性和上市时间优势的能力越来越依赖于可编程逻辑设备支持不断增加的各种I/O标准的能力
多用途I/O资源具有高度可配置的输入和输出缓冲区,为各种I/O标准提供支持。
支持的I/O标准概述
虽然大多数I/O标准规定了允许的电压范围,但本文件仅记录典型的电压值。有关每个规范的详细信息,请访问电子工业联盟jedec网站h
LVTTL-低压TTL
低压ttl(lvttl)标准是一个通用的eia/jesdsa标准,适用于使用lvttl输入缓冲区和推拉输出缓冲区的3.3v应用。本标准要求3.3V输出源电压(VCCO),但不要求使用参考电压(VREF)或终端电压(VTT)。
2.5V低压CMOS
用于2.5v或更低(lvcmos2)标准的低压cmos是用于一般2.5v应用的lvcmos标准(jesd 8.5)的扩展。本标准要求2.5V输出源电压(VCCO),但不要求使用参考电压(VREF)或板端电压(VTT)。
PCI-外围组件接口
外围组件接口(PCI)标准指定支持33 MHz和66 MHz PCI总线应用程序。它使用lvttl输入缓冲区和推拉输出缓冲区。本标准不要求使用参考电压(VREF)或电路板端接电压(VTT),但要求3.3V输出源电压(VCCO)。为PCI、33 MHz、5V标准配置的I/O也允许5V。
GTL-喷枪收发机逻辑终止
喷枪收发器逻辑(gtl)标准是xerox公司发明的一种高速总线标准(jesd8.3)。xilinx实现了本标准的终止变更。本标准要求差动放大器输入缓冲器和开路漏极输出缓冲器。
GTL+-喷枪收发器逻辑增强
喷枪收发器逻辑增强(GTL+)标准是奔腾Pro处理器首次使用的高速总线标准(Jesd8.3)。
高速收发器逻辑
高速收发器逻辑(hstl)标准是由ibm(eia/jesd 8-6)发起的通用高速1.5v总线标准。本标准有四个变体或等级。通用I/O设备支持I、III和IV类。本标准要求差动放大器输入缓冲器和推挽输出缓冲器。
sstl3-3.3v的存根系列终止逻辑
用于3.3V(SSTL3)标准的存根系列端接逻辑是一种通用的3.3V内存总线标准,也由日立和IBM(Jesd8-8)赞助。本标准分为I类和II类。多功能I/O设备支持SSTL3标准的两个类。本标准要求差分放大器输入缓冲器和推挽输出缓冲器。
SSTL2-2.5V短串端接逻辑
用于2.5V(SSTL2)标准的存根系列端接逻辑是日立和IBM(Jesd8-9)赞助的通用2.5V内存总线标准。本标准分为I类和II类。多功能I/O设备支持SSTL2标准的两个类。本标准要求差分放大器输入缓冲器和推挽输出缓冲器。
CTT-中心抽头终止
中心抽头端接(CTT)标准是富士通(Jesd8-4)赞助的3.3V内存总线标准。本标准要求差动放大器输入缓冲器和推挽输出缓冲器。
AGP-2X-高级图形端口
英特尔AGP标准是一种3.3V高级图形端口2x总线标准,与奔腾II处理器一起用于图形应用。本标准要求推拉输出缓冲器和差分放大器输入缓冲器。
库符号
xilinx库包含了一个广泛的符号列表,这些符号旨在支持多种多样的i/o特性。这些符号中的大多数表示五种通用通用I/O符号的变体:
8226;IBUF(输入缓冲区)
•IBUFG(全局时钟输入缓冲区)
•obuf(输出缓冲区)
•OBUFT(三态输出缓冲器)
•IOBUF(输入/输出缓冲区)
设计注意事项
参考电压(V)引脚裁判
带有差动放大器输入缓冲器的低压I/O标准需要输入参考电压(VREF)。提供VREF作为设备的外部信号。
电压参考信号在设备内以半边缘方式“排列”,以便所有封装内部都有八个独立的VREF排列。有关I/O银行的表示,请参见第32页图35。在每个组中,大约每六个I/O引脚中的一个自动配置为VREF输入。
在每个vref组中,需要vref信号的任何输入缓冲器必须是相同类型的。任何类型的输出缓冲器和输入缓冲器都可以放置在同一个VREF组内,无需参考电压。
输出驱动源电压(V)引脚CCO
多功能i/o支持的许多低电压i/o标准需要不同的输出驱动源电压(vcco)。因此,每个设备通常必须支持多个输出驱动源电压。
VCCO的供应是内部捆绑在一起的一些包。VQ100和PQ208提供一个组合VCCO电源。TQ144和CS144封装提供四个独立的VCCO电源。fg256和fg456提供八个独立的vcco电源。
给定vcco库中的输出缓冲区必须共享相同的输出驱动源电压。lvttl、lvcmos2、pci33_3和pci 66_3的输入缓冲区使用vcco电压作为输入vcco电压。
传输线效应
电信号沿导线的延迟取决于信号在短距离传播时的上升和下降时间。传输线延迟随电感和电容的变化而变化,但设计良好的电路板每英寸可经历大约180 ps的延迟。
传输线效应或反射通常从1.5英寸开始,用于快速(1.5纳秒)上升和下降时间。不良(或不存在)终端或传输线阻抗的变化会导致这些反射,并可能在较长的记录道中造成额外延迟。随着系统速度的不断提高,i/o延迟的影响可能成为限制因素,因此传输线终端变得越来越重要。
同时切换指南
当多个输出同时改变状态时,高速数字集成电路可能会发生接地弹跳,导致输出或内部逻辑出现不希望的瞬态行为。这个问题也被称为同时开关输出(sso)问题。
接地弹跳主要是由于接地引脚、连接线和接地金属化的组合电感的电流变化。在多个输出同时改变状态后,IC内部接地电平在短时间内(几纳秒)偏离外部系统接地电平。
接地反弹影响稳定的低输出和所有输入,因为它们通过将输入信号与内部接地进行比较来解释输入信号。如果地面反弹幅度超过实际瞬时噪声裕度,则不改变的输入可以解释为极性与地面反弹相反的短脉冲。
开关特性
开关参数的测试按照mil-m-38510/605规定的测试方法进行建模。所有设备都经过100%功能测试。内部计时参数是通过测量内部测试模式得到的。下面列出的是代表性值。对于更具体、更精确和最坏情况下有保证的数据,请使用静态定时分析器(xilinx开发系统中的trce)报告的值,并将其重新注释到仿真网络列表中。所有的定时参数都假定了最坏的工作条件(电源电压和结温)。除非另有说明,否则该值适用于所有斯巴达II设备。
