STM32的标准外设库、HAL、LL软件库,都有很多巧妙之处值得大家借鉴。
今天讲讲STM32Cbue LL库中巧妙运用“静态内联”使代码更高效。
概述
有些应用要求MCU能高效处理,特别是跑一些算法时,对CPU执行效率要求较高。
网上有很多文章说STM32CubeHAL执行效率不高,代码量大等问题,导致很多还没有入门,或初学的读者就产生各种各样的疑惑。
说实话,HAL相对标准外设库来说确实存在代码效率不高、代码量大灯这些问题,那么与之对应的STM32Cube LL恰好避免了这样的问题。
LL能高效的原因
简单总结一下原因:巧妙运用C语言静态、内联函数直接操作寄存器。
当然,这是其中重要的原因,还有一些其它原因,这里暂不描述。
你会在LL库.h文件中发现大量类似,静态、内联函数直接读写寄存器的函数。
比如读写IO口:

其中__STATIC_INLINE,就是静态、内联:

而读写位的定义:
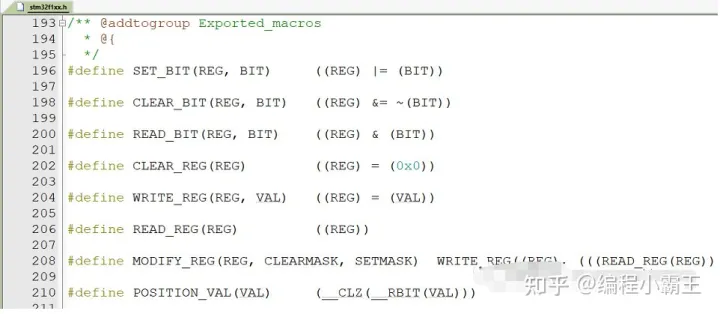
这里面的宏定义,在众多外设.h中都在调用。比如使能USART:
LL库使能USART:

标准外设库使能USART:
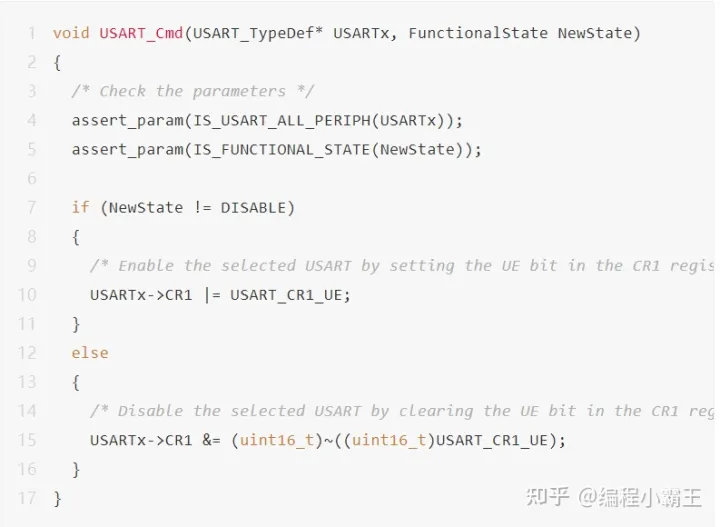
通过对比,你会明显发现:LL库的执行效率更高。
什么是内联函数
写到这里,就可能有读者会问:什么是内联函数?

通常,程序执行时,处理器从内存中读取代码执行。当程序中调用一个函数时,程序跳到存储器中保存函数的位置,开始读取代码执行,执行完后再返回。
为了提高速度,C语言定义了inline函数,告诉编译器把函数代码在编译时直接拷贝到程序中,这样就不用执行时另外读取函数代码。
提示:
当内联函数很大时,会有相反的作用,因此一般比较小的函数才使用内联函数。
软件框架思维
LL之所以高效,是因为它巧妙运用了一些C语言知识,没有太多封装,直接或间接对寄存器进行操作。
而能这样实现,归功于ST开发团队设计了这么一个中间层软件框架。
对于有大型项目开发经验的人来说,一个项目的框架对整个项目影响很大。
就好比你建一栋楼,如果楼层框架都没造好,你觉得这栋楼质量会好吗?
所以,这里就提到,我们编程时,特别项目较大,需要考虑一下软件框架,一个好的框架能让你你的项目达到事半功倍的效果。
