MAX78000 点击型号即可查看芯片规格书
近年来,由声控用户界面驱动的数字助理的应用急剧增加。虽然一些产品严重依赖云连接来在功能强大的远程服务器上执行语音识别算法和自然语言处理,但在低功耗设备上不断将音频流式传输到云端进行处理是不可行的。特别是,唤醒关键字的检测以及有限的命令字集有望在本地完成,以优化物联网和边缘应用中的功耗并减少延迟。MAX78000是一款超低功耗微控制器,带有卷积神经网络(CNN)加速器,可有效覆盖此类应用。
cnn在声学系统建模,尤其是关键词检测方面非常流行。与常规神经网络一样,cnn是由一系列具有权重和偏差的神经元构成的,然后是非线性。然而,卷积层每次只查看带有最后一层输出神经元的一小部分的局部区域,并在每次执行时将其滑动到最后一层(图1)。池化层经常与CNN一起使用,以对最后一层的输出进行下采样。这些操作是MAX78000 CNN架构的核心,该架构采用64个并行处理器,每个处理器都有一个池化单元、一个卷积引擎和一个专用权重存储器。
本应用笔记探讨了如何在MAX78000上实现关键字定位应用程序,MAX78000是一款带有CNN加速器的超低功耗微控制器。从第二版Google语音命令数据集中选取20个关键词进行关键字识别演示训练(KWS20)。

图1所示 CNN的基本操作
MAX78000([1])是一款新型人工智能(AI)微控制器,旨在使神经网络能够以超低功耗执行,并在物联网的边缘运行。该产品结合了最节能的人工智能处理和Maxim的超低功耗微控制器。基于硬件的CNN加速器使电池供电的应用程序能够在只消耗微焦耳能量的情况下执行人工智能推理。这使得它成为关键字定位应用程序的理想架构。MAX78000采用Arm Cortex -M4和FPU CPU,通过超低功耗深度神经网络加速器实现高效的系统控制。图2显示了MAX78000的顶层架构。

图2 MAX78000的结构
MAX78000评估套件提供了一个平台,可以利用MAX78000的功能来构建新一代人工智能设备。EV套件具有板载硬件,如数字麦克风,串行端口,摄像头模块支持,以及用于KWS20演示应用的3.5英寸触摸式彩色薄膜晶体管(TFT)显示器[2](图3)。

图3 在MAX78000EVKIT上进行关键字定位演示
PyTorch或TensorFlow-Keras工具链可用于开发MAX78000的模型。该模型是用一系列表示硬件的已定义子类创建的。一些操作,如池化或激活,融合到1D或2D卷积层,以及完全连接的层。还添加了舍入和裁剪以匹配硬件。
使用浮点权值和训练数据对模型进行训练。权重既可以在训练期间量化(量化感知训练),也可以在训练后量化(训练后量化)。量化结果可以在评估数据集上进行评估,以检查权重量化导致的精度下降。
MAX78000合成器工具(ai8xize)接受PyTorch检查点或TensorFlow导出的ONNX文件作为输入,以及YAML格式的模型描述。示例数据文件(。Npy文件)也提供给合成器以验证硬件上的合成模型。将该数据的推理结果与预合成模型的预期输出进行比较。
MAX78000合成器自动生成可在MAX78000上编译和执行的C代码。C代码包括应用程序编程接口(API)调用,用于将权重和提供的示例数据加载到硬件,以便对示例数据执行推理,并将分类结果与预期结果进行比较,作为通过/失败的完整性测试。生成的C代码可以用作创建自己的应用程序的示例。图4显示了MAX78000的整体开发流程。

图4 MAX78000的开发流程
Mel Frequency倒频谱系数(MFCC)是一种知名且流行的特征提取方法[3]。特征提取的目的是用一组已知的、相关的成分来表示语音信号,用于分类。
MFCC通过使用滤波器组实现信号分解。它提供了Mel频率尺度上短期能量的实对数的离散余弦变换(DCT)。更具体地说,MFCC的计算流程包括:将语音信号开窗成帧,执行快速傅里叶变换(FFT)以找到每帧的功率谱,使用Mel尺度进行滤波器组处理,最后对功率谱的对数尺度进行DCT(图5)。

图5 Arm上的MFCC处理(初始模型)
语音数据在微控制器上进行预处理以生成MFCC来实现这种方法。FFT、滤波、日志和DCT必须在MAX78000的Arm处理器固件中实现。接下来,CNN对语音数据样本的MFCC进行推断。这个模型最初是为了这个应用程序而研究的。
研究了另一种方法来创建两个独立的cnn并提高效率。训练了一个MFCC估计网络(melspectrum net)来提供给定波形的实际MFCC的近似值。使用第二个KWS20分类器网络从估计的MFCC中对关键词进行分类。在这种方法中,CNN加速器依次运行MFCC和KWS20网络。MFCC操作将时间序列样本转换为二维(2D)空间。这是使用一系列1D卷积层来建模的。KWS20分类器接收2D类图像数据,并将其传递给几个2D卷积层。

图6 CNN上的MFCC近似(第二种方法)
在第三个演示方法中,使用原始数据训练单个组合网络来识别类,而不是为MFCC和分类使用两个单独的cnn。该方法简化了训练,减小了网络的大小,但没有显著的性能下降。该网络由一系列模拟MFCC逼近器的1D卷积层组成,然后是几个2D卷积层。最后的密集层生成每个类的最大似然。选择这种方法(图7)来构建KWS20演示,如下面的部分所述。

图7 演示模型:结合CNN和原始数据作为输入
本练习使用由Google([4][5])创建的语音命令数据集的版本2。该数据集由超过100k的35个不同单词的话语组成,存储为以16kHz采样的一秒。wave格式文件。35个单词中的20个被选为期望类别,其余的被标记为未知类别。表1显示了选中的关键字。
| 类代码 | 词 | 说话次数 | 类代码 | 词 | 说话次数 | 类代码 | 词 | 说话次数 |
| 0 | 向上 | 3723 | 7 | 没有 | 3941 | 14 | 五个 | 4052 |
| 1 | 下来 | 3917 | 8 | 在 | 3845 | 15 | 六个 | 3860 |
| 2 | 左 | 3801 | 9 | 从 | 3745 | 16 | 七个 | 3998 |
| 3. | 正确的 | 3778 | 10 | 一个 | 3890 | 17 | 八个 | 3787 |
| 4 | 停止 | 3872 | 11 | 两个 | 3880 | 18 | 九个 | 3934 |
| 5 | 去 | 3880 | 12 | 三个 | 3727 | 19 | 零 | 4052 |
| 6 | 是的 | 4044 | 13 | 四个 | 3728 | 20. | 未知的 | 28375 |
未知类别的话语数量明显高于其他类别,因为它包含了所有其余15个类别的总和。这就导致了未知类相对于其他类的过度训练。CrossEntropyLoss函数(PyTorch)中未知类的权重被设置为其他类权重的0.14以解决此问题。
每个波形都用额外的噪声、时移和随机拉伸增强两次,以进一步增强数据集,从而使原始数据集大小增加3倍。增强后的网络在有背景噪声的真实环境下的性能得到了提高。图8给出了一个在增强前后使用Stop的例子。
增强的数据集被划分为训练、验证和测试类别(表2)。
默认的TensorFlow数据格式是channel last。Conv1D操作的预期输入形状是batch_size、width和channels, Conv2D操作的预期输入形状是batch_size、height、width和channels。
按顺序读取样本并存储在128行中,以生成1 x 128 x 128张量用于训练目的。图9a显示了发送到CNN之前的Stop数据样本的图像表示。
另一方面,合成器的格式是通道优先,就像PyTorch一样。训练脚本为每个类生成一个示例样本数据文件,供合成器用于验证。通过转换数据集样本,将这些样例类数据文件转换为通道优先格式。图9b显示了为合成器转置的相同样本。
| 类别 | 说话次数 |
| 培训 | 197751 |
| 验证 | 21972 |
| 测试 | 68250 |

图8 增强前后的Stop波形
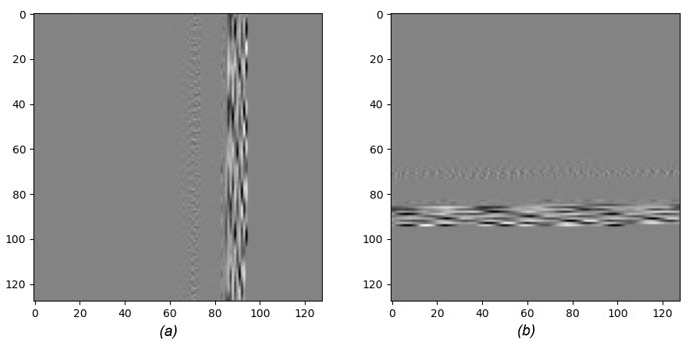
图9 以128 × 128图像表示的Stop波形:
a.被送入网络进行训练。
b.转置以用于合成脚本。
组合关键词识别CNN被训练来对原始数据进行分类。该模型由两个背靠背的cnn组成:1D (Conv1D)和2D (Conv2D)卷积网络。Conv1D CNN包括四层,提取语音特征。Conv2D CNN包括五层,然后是一个完全连接的层,用于对话语进行分类。该模型使用20个关键词的增强数据集进行训练(表1)。图10显示了CNN模型。

图10 PyTorch中的关键字定位模型
模型训练由以下脚本执行:
$ ./train_kws20.sh
该脚本自动下载Google语音命令版本2数据集,使用上述增强技术对其进行扩展,并完成训练。图11显示了模型训练的结果。

图11 模型训练的例子
训练过程中产生的CNN权值必须量化为8位。CNN权重量化是通过执行以下脚本完成的:
$ ./quantize_kws20.sh
可以通过执行以下脚本对量化模型进行评估:
(ai8x-training) $ ./evaluate_kws20.sh
图12给出了模型的评价结果。
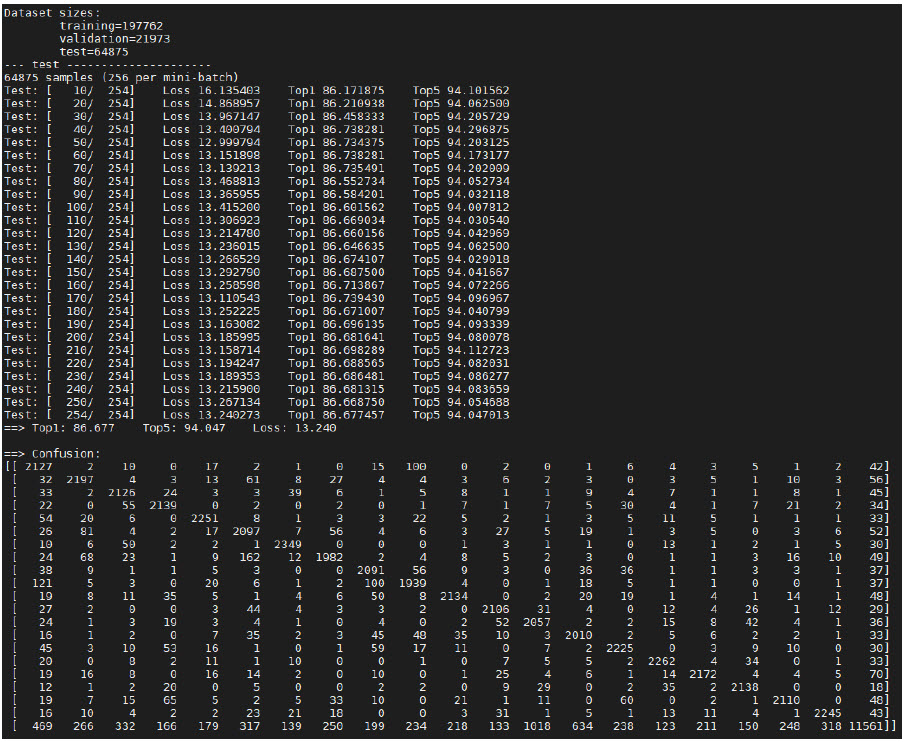
图12 量化后的模型评价和混淆矩阵示例
网络合成脚本生成一个通过/失败示例C代码,该代码包含初始化MAX78000 CNN加速器、加载量化CNN权重以及提供的输入样本、卸载分类结果以与预期输出进行比较的必要函数。合成工具需要三个输入(图4):
量化PyTorch检查点文件或TensorFlow模型导出到ONNX格式。
网络模型的YAML描述。
包含预期结果的示例输入,将包含在生成的C代码中以进行验证。
合成脚本生成如图13所示的输出文件。

图13 生成MAX78000示例源代码
示例代码可以编译并部署到MAX78000上。图14显示了带有每个类的置信度的执行结果。

图14 关键词定位模型执行结果
以基本的C代码为基础构建KWS20演示平台。CNN初始化、权重(内核)以及加载/卸载权重和示例的辅助函数从生成的示例代码移植到下一节中描述的KWS20演示中。
KWS20固件演示了MAX78000 EV套件上的关键字检测,如图15所示。板载I(2)S麦克风采样18位,16kHz音频信号,并流式传输到MAX78000。一个简单的高通滤波器用于消除麦克风的直流偏移,并将样本存储在圆形缓冲器中。信号电平在128个采样窗口上平均,并与可调阈值进行比较,以找到单词的开头。低于这个阈值的水平被归类为话语中单词之前的沉默。一旦信号电平超过阈值,就会检测到单词的开头。在CNN加速器上启动推理需要16kHz, 8位采样(1秒)。语音结束时的信号电平被监控。如果平均水平达到并保持在几个连续128个样本窗口的可调阈值以下,或者已经收集了16k个样本,则可以开始推断。该网络在CNN加速器上的推理时间约为2.5ms。推理结果和置信水平显示在显示器和串口上([6])。图16总结了KWS20演示FW中的处理流程。

图15 MAX78000 EV套件上的KWS20

图16 KWS20演示固件的处理流程
本应用笔记演示了20个关键字检测模型的实现以及在超低功耗MAX78000平台上的最终部署,用于资源受限的边缘或物联网应用。它还重点介绍了MAX78000架构,并描述了构建机器学习模型的开发流程,该模型将关键字定位作为目标应用程序。
